- PrivaceraCloud Release 7.4
- Enhancements and updates in PrivaceraCloud release 7.4
- Known Issues in PrivaceraCloud 7.4
- PrivaceraCloud User Guide
- Overview of PrivaceraCloud
- Connect applications with the setup wizard
- Connect applications
- About applications
- Connect Azure Data Lake Storage Gen 2 (ADLS) to PrivaceraCloud
- Connect Amazon Textract to PrivaceraCloud
- Athena
- Privacera Discovery with Cassandra
- Connect Databricks to PrivaceraCloud
- Databricks SQL
- Databricks SQL Overview and Configuration
- Planning and general process
- Prerequisites
- Databricks SQL with Privacera Hive
- Connect Databricks SQL application
- Grant Databricks SQL permissions to PrivaceraCloud users
- Define a resource policy
- Test the policy
- Databricks SQL PolicySync fields
- Configuring column-level access control
- View-based masking functions and row-level filtering
- Create an endpoint in Databricks SQL
- Databricks SQL Fields
- Databricks SQL Hive Service Definition
- Databricks SQL Masking Functions
- Databricks SQL Encryption
- Use a custom policy repository with Databricks
- Connect Databricks SQL to Hive policy repository on PrivaceraCloud
- Databricks SQL Overview and Configuration
- Connect Databricks Unity Catalog to PrivaceraCloud
- Connect S3 to PrivaceraCloud
- Prerequisites in AWS console
- Connect S3 application to PrivaceraCloud
- Enable Privacera Access Management for S3
- Enable Data Discovery for S3
- S3 AWS Commands - Ranger Permission Mapping
- S3
- AWS Access with IAM
- Access AWS S3 buckets from multiple AWS accounts
- Add UserInfo in S3 Requests sent via Dataserver
- Control access to S3 buckets with AWS Lambda function on PrivaceraCloud
- Dremio Plugin
- DynamoDB
- Connect Elastic MapReduce from Amazon application to PrivaceraCloud
- Connect EMR application
- EMR Spark access control types
- PrivaceraCloud configuration
- AWS IAM roles using CloudFormation setup
- Create a security configuration
- Create EMR cluster
- How to configure multiple JSON Web Tokens (JWTs) for EMR
- EMR Native Ranger Integration with PrivaceraCloud
- Connect EMRFS S3 to PrivaceraCloud
- Files
- GBQ
- Google Cloud Storage
- Connect Glue to PrivaceraCloud
- Google BigQuery for PolicySync
- Connect Kinesis to PrivaceraCloud
- Connect Lambda to PrivaceraCloud
- Microsoft SQL Server
- MySQL for Discovery
- Open Source Apache Spark
- Oracle for Discovery
- PostgreSQL
- Connect Power BI to PrivaceraCloud
- Presto
- Redshift
- Snowflake
- Starburst Enterprise with PrivaceraCloud
- Starburst Enterprise Presto
- Trino
- Connect users
- Data access Users, Groups, and Roles
- UserSync
- Portal user LDAP/AD
- Datasource
- Okta Setup for SAML-SSO
- Azure AD setup
- SCIM Server User-Provisioning
- User Management
- Identity
- Access Manager
- Access Manager
- Resource Policies
- Tag Policies
- Scheme Policies
- Service Explorer
- Reports
- Audit
- About data access users, groups, and roles resource policies
- Security zones
- Discovery
- Classifications via random sampling
- Privacera Discovery scan targets
- Propagate Privacera Discovery Tags to Ranger
- Enable offline scanning on Azure Data Lake Storage Gen 2 (ADLS)
- Enable Real-time Scanning of S3 Buckets
- Enable Real-time Scanning on Azure Data Lake Storage Gen 2 (ADLS)
- Enable Discovery Realtime Scanning Using IAM Role
- Encryption
- Overview of Privacera Encryption
- Encryption schemes
- Presentation schemes
- Masking schemes
- Create scheme policies
- Privacera-supplied encryption schemes for the Privacera API
- Privacera-supplied encryption schemes for the Bouncy Castle API
- API date input formats
- Deprecated encryption formats, algorithms, and scopes
- Privacera Encryption REST API
- PEG API endpoint
- PEG REST API encryption endpoints
- Prerequisites
- Common PEG REST API fields
- Construct the datalist for the /protect endpoint
- Deconstruct the response from the /unprotect endpoint
- Example data transformation with the /unprotect endpoint and presentation scheme
- Example PEG API endpoints
- Make encryption API calls on behalf of another user
- Privacera Encryption UDF for masking in Databricks on PrivaceraCloud
- Privacera Encryption UDFs for Trino on PrivaceraCloud
- Syntax of Privacera Encryption UDFs for Trino
- Prerequisites for installing Privacera Crypto plug-in for Trino
- Download and install Privacera Crypto jar
- Set variables in Trino etc/crypto.properties
- Restart Trino to register the Privacera encryption and masking UDFs for Trino
- Example queries to verify Privacera-supplied UDFs
- Privacera Encryption UDF for masking in Trino on PrivaceraCloud
- Encryption UDFs for Apache Spark on PrivaceraCloud
- Launch Pad
- Settings
- Dashboard
- Usage statistics
- Operational status of PrivaceraCloud and RSS feed
- How to Get Support
- Coordinated Vulnerability Disclosure (CVD) Program of Privacera
- Shared Security Model
- PrivaceraCloud Previews
- Preview: File Explorer for S3
- Preview: File Explorer for Azure
- Preview: File Explorer for GCS
- Preview: Scan Generic Records with NER Model
- Preview: Scan Electronic Health Records with NER Model
- Preview: OneLogin setup for SAML-SSO
- Preview: Azure Active Directory SCIM Server UserSync
- Preview: OneLogin UserSync
- Preview: PingFederate UserSync
- Quickstart for Databricks Unity Catalog on PrivaceraCloud
- What do I need to do in my Databricks Workspace?
- Where is the sample dataset in my Databricks Workspace?
- What should I do in the PrivaceraCloud web portal?
- Access use-case - How do I give a user access to a table or restrict from running a SQL select query?
- Access use-case - How do I restrict a user from seeing contents of a column in the result of a SQL select query?
- Column masking use-case - How do I restrict a user from seeing contents of a column by masking the values in the result of a SQL select query?
- Access use-case - How do I disallow a user from seeing certain rows of a table?
- PrivaceraCloud documentation changelog
Connect Databricks to PrivaceraCloud
The topic describes how to connect Databricks application to PrivaceraCloud using AWS and Azure platforms. Privacera provides Spark Fine-Grained Access Control plug-in [FGAC] and Spark Object-Level Access Control plug-in [OLAC] plugin solutions for access control in Databricks clusters. Both plugins are mutually exclusive and cannot be enabled on the same cluster.
Go the Setting > Applications.
In the Applications screen, select Databricks.
Select the platform type (AWSor Azure) on which you want to configure the Databricks application.
Enter the application Name and Description, and then click Save.
Click the toggle button to enable Access Management for Databricks.
Databricks Spark Fine-Grained Access Control plug-in [FGAC]
PrivaceraCloud integrates with Databricks SQL using the Plug-In integration method with an account-specific cluster-scoped initialization script. Privacera’s Spark plug-In will be installed on the Databricks cluster enabling Fine-Grained Access Control. This script will be added it to your cluster as an init script to run at cluster startup. As your cluster is restarted, it runs the init script and connects to PrivaceraCloud.
Prerequisites
Ensure that the following prerequisites are met:
You must have an existing Databricks account and login credentials with sufficient privileges to manage your Databricks cluster.
PrivaceraCloud portal admin user access.
This setup is recommended for SQL, Python, and R language notebooks.
It provides FGAC on databases with row filtering and column masking features.
It uses privacera_hive, privacera_s3, privacera_adls, privacera_files services for resource-based access control, and privacera_tag service for tag-based access control.
It uses the plugin implementation from Privacera.
Obtain Init Script for Databricks FGAC
Log in to the PrivaceraCloud portal as an admin user (role ROLE_ACCOUNT_ADMIN).
Generate the new API and Init Script. For more information, see API Key.
On the Databricks Init Script section, click DOWNLOAD SCRIPT.
By default, this script is named
privacera_databricks.sh. Save it to a local filesystem or shared storage.Log in to your Databricks account using credentials with sufficient account management privileges.
Copy the Init script to your Databricks cluster. This can be done via the UI or using the Databricks CLI.
Using the Databricks UI:
On the left navigation, click the Data icon.
Click the Add Data button from the upper right corner.
In the Create New Table dialog, select Upload File, and then click browse.
Select
privacera_databricks.sh, and then click Open to upload it.Once the file is uploaded, the dialog will display the uploaded file path. This filepath will be required in the later step.
The file will be uploaded to
/FileStore/tables/privacera_databricks.shpath, or similar.
Using the Databricks CLI, copy the script to a location in DBFS:
databricks fs cp ~/<sourcepath_privacera_databricks.sh> dbfs:/<destinaton_path>
For example:
databricks fs cp ~/Downloads/privacera_databricks.sh dbfs:/FileStore/tables/
You can add PrivaceraCloud to an existing cluster, or create a new cluster and attach PrivaceraCloud to that cluster.
a. In the Databricks navigation panel select Clusters.
b. Choose a cluster name from the list provided and click Edit to open the configuration dialog page.
c. Open Advanced Options and select the Init Scripts tab.
d. Enter the DBFS init script path name you copied earlier.
e. Click Add.
f. From Advanced Options, select the Spark tab. Add the following Spark configuration content to the Spark Config edit window. For more information on the properties, see Spark Properties.
For OLAC on AWS to read S3 files, whether an IAM role is needed depends on which services you are accessing:
If you are accessing only S3 and not accessing any other AWS services, do not associate any IAM role with the Databricks cluster. OLAC for S3 access relies on the Privacera Data Access Server.
If you are accessing services other than S3, such as Glue or Kinesis, create an IAM role with minimal permission and associate that IAM role with those services.
For OLAC on Azure to read ADLS files, make sure the Databricks cluster does not have the Azure shared key or passthrough configured. OLAC for ADLS access relies on the Privacera Data Access Server.
New Properties:
spark.databricks.isv.product privacera spark.databricks.cluster.profile serverless spark.databricks.delta.formatCheck.enabled false spark.driver.extraJavaOptions -javaagent:/databricks/jars/privacera-agent.jar spark.databricks.repl.allowedLanguages sql,python,r
Old Properties:
spark.databricks.isv.product privacera spark.databricks.cluster.profile serverless spark.databricks.delta.formatCheck.enabled false spark.driver.extraJavaOptions -javaagent:/databricks/jars/ranger-spark-plugin-faccess-2.0.0-SNAPSHOT.jar spark.databricks.repl.allowedLanguages sql,python,r
Note
From PrivaceraCloud release 4.1.0.1 and later, it is recommended to replace the Old Properties with the New Properties. However, the Old Properties will also continue to work.
For Databricks versions <=8.2, Old Properties should only be used since the versions are in extended support.
If you are upgrading the Databricks Runtime from an existing version (6.4-8.2) to a version 8.3 and higher, contact Privacera technical sales representative for assistance.
Restart the Databricks cluster.
Validate installation
Confirm connectivity by executing a simple data access sequence and then examining the PrivaceraCloud audit stream.
You will see corresponding events in the Access Manager > Audits.
Example data access sequence:
Create or open an existing Notebook. Associate the Notebook with the Databricks cluster you secured in the steps above.
Run an SQL show tables command in the Notebook:
sql show tables ;
On PrivaceraCloud, go to Access Manager > Audits to view the monitored data access.
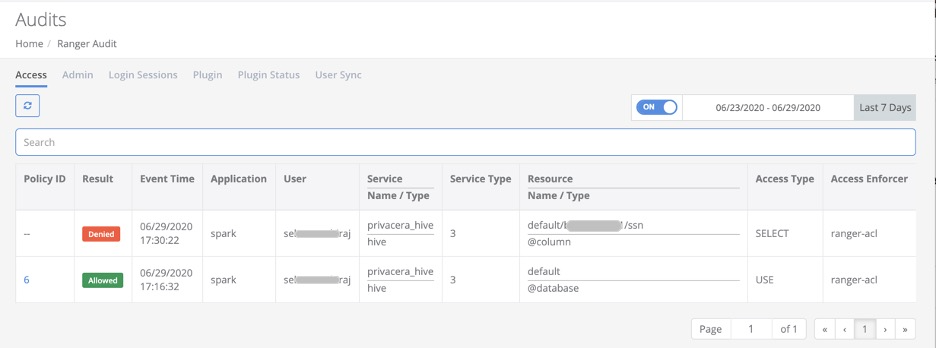
Create a Deny policy, run this same SQL access sequence a second time, and confirm corresponding Denied events.
Databricks Spark Object-Level Access Control plug-in [OLAC]
This section outlines the steps needed to setup Object-Level Access Control (OLAC) in Databricks clusters. This setup is recommended for Scala language notebooks.
It provides OLAC on S3 locations accessed via Spark.
It uses privacera_s3 service for resource-based access control and privacera_tag service for tag-based access control.
It uses the signed-authorization implementation from Privacera.
Note
If you are using SQL, Python, and R language notebooks, recommendation is to use FGAC. See the Databricks Spark Fine-Grained Access Control plug-in [FGAC] section above.
OLAC and FGAC methods are mutually exclusive and cannot be enabled on the same cluster.
OLAC plugin was introduced to provide an alternative solution for Scala language clusters, since using Scala language on Databricks Spark has some security concerns.
Prerequisites
Ensure that the following prerequisites are met:
You must have an existing Databricks account and login credentials with sufficient privileges to manage your Databricks cluster.
PrivaceraCloud portal admin user access.
Steps
Note
For working with Delta format files, configure the AWS S3 application using IAM role permissions.
Create a new AWS S3 Databricks connection. For more information, see Connect S3 to PrivaceraCloud.
After creating an S3 application:
In the BASIC tab, provide Access Key, Secret Key, or an IAM Role.
In the ADVANCED tab, add the following property:
dataserver.databricks.allowed.urls=<DATABRICKS_URL_LIST>
where
<DATABRICKS_URL_LIST>: Comma-separated list of the target Databricks cluster URLs.For example:
dataserver.databricks.allowed.urls=https://dbc-yyyyyyyy-xxxx.cloud.databricks.com/.Click Save.
If you are updating an S3 application:
Go to Settings > Applications > S3, and click the pen icon to edit properties.
Click the toggle button of a service you wish to enable.
In the ADVANCED tab, add the following property:
dataserver.databricks.allowed.urls=<DATABRICKS_URL_LIST>
where
<DATABRICKS_URL_LIST>: Comma-separated list of the target Databricks cluster URLs. For example,dataserver.databricks.allowed.urls=https://dbc-yyyyyyyy-xxxx.cloud.databricks.com/.Save your configuration.
Download the Databricks init script:
Log in to the PrivaceraCloud portal.
Generate the new API and Init Script. For more information, refer to the topic API Key on PrivaceraCloud.
On the Databricks Init Script section, click the DOWNLOAD SCRIPT button.
By default, this script is named
privacera_databricks.sh. Save it to a local filesystem or shared storage.
Upload the Databricks init script to your Databricks clusters:
Log in to your Databricks cluster using administrator privileges.
On the left navigation, click the Data icon.
Click Add Data from the upper right corner.
From the Create New Table dialog box select Upload File, then select and open
privacera_databricks.sh.Copy the full storage path onto your clipboard.
Add the Databricks init script to your target Databricks clusters:
In the Databricks navigation panel select Clusters.
Choose a cluster name from the list provided and click Edit to open the configuration dialog page.
Open Advanced Options and select the Init Scripts tab.
Enter the DBFS init script path name you copied earlier.
Click Add.
From Advanced Options, select the Spark tab. Add the following Spark configuration content to the Spark Config edit window. For more information on the properties, see Spark Properties
New Properties
spark.databricks.isv.product privacera spark.databricks.repl.allowedLanguages sql,python,r,scala spark.driver.extraJavaOptions -javaagent:/databricks/jars/privacera-agent.jar spark.executor.extraJavaOptions -javaagent:/databricks/jars/privacera-agent.jar spark.databricks.delta.formatCheck.enabled false
Add the following property in the Environment Variables text box:
PRIVACERA_PLUGIN_TYPE=OLAC
Old Properties
spark.databricks.isv.product privacera spark.databricks.repl.allowedLanguages sql,python,r,scala spark.driver.extraJavaOptions -javaagent:/databricks/jars/ranger-spark-plugin-faccess-2.0.0-SNAPSHOT.jar spark.hadoop.fs.s3.implcom.databricks.s3a.PrivaceraDatabricksS3AFileSystem spark.hadoop.fs.s3n.implcom.databricks.s3a.PrivaceraDatabricksS3AFileSystem spark.hadoop.fs.s3a.implcom.databricks.s3a.PrivaceraDatabricksS3AFileSystem spark.executor.extraJavaOptions -javaagent:/databricks/jars/ranger-spark-plugin-faccess-2.0.0-SNAPSHOT.jar spark.hadoop.signed.url.enable true
Properties to enable JWT Auth:
privacera.jwt.oauth.enable true privacera.jwt.token /tmp/ptoken.dat
Save and close.
Restart the DatabricksCluster.
Note
From PrivaceraCloud release 4.1.0.1 onwards, it is recommended to replace the Old Properties with the New Properties. However, the Old Properties will also continue to work.
For Databricks versions <= 8.2, Old Properties should only be used since the versions are in extended support.
If you are upgrading the Databricks Runtime from an existing version (6.4-8.2) to a version 8.3 and higher, contact Privacera technical sales representative for assistance.
Your S3 Databricks cluster data resource is now available for Access Manager Policy Management, under Access Manager > Resource Policies, Service "privacera_s3".
Databricks cluster deployment matrix with Privacera plugin
Job/Workflow use-case for automated cluster:
Run-Now will create the new cluster based on the definition mentioned in the job description.
Job Type | Languages | FGAC/DBX version | OLAC/DBX Version |
|---|---|---|---|
Notebook | Python/R/SQL | Supported [7.3, 9.1 , 10.4] | |
JAR | Java/Scala | Not supported | Supported[7.3, 9.1 , 10.4] |
spark-submit | Java/Scala/Python | Not supported | Supported[7.3, 9.1 , 10.4] |
Python | Python | Supported [7.3, 9.1 , 10.4] | |
Python wheel | Python | Supported [9.1 , 10.4] | |
Delta Live Tables pipeline | Not supported | Not supported |
Job on existing cluster:
Run-Now will use the existing cluster which is mentioned in the job description.
Job Type | Languages | FGAC/DBX version | OLAC |
|---|---|---|---|
Notebook | Python/R/SQL | supported [7.3, 9.1 , 10.4] | Not supported |
JAR | Java/Scala | Not supported | Not supported |
spark-submit | Java/Scala/Python | Not supported | Not supported |
Python | Python | Not supported | Not supported |
Python wheel | Python | supported [9.1 , 10.4] | Not supported |
Delta Live Tables pipeline | Not supported | Not supported |
Interactive use-case
Interactive use-case is running a notebook of SQL/Python on an interactive cluster.
Cluster Type | Languages | FGAC | OLAC |
|---|---|---|---|
Standard clusters | Scala/Python/R/SQL | Not supported | Supported [7.3,9.1,10.4] |
High Concurrency clusters | Python/R/SQL | Supported [7.3,9.1,10.4 | Supported [7.3,9.1,10.4] |
Single Node | Scala/Python/R/SQL | Not supported | Supported [7.3,9.1,10.4] |
Access AWS S3 using Boto3 from Databricks
This section describes how to use the AWS SDK (Boto3) for PrivaceraCloud to access AWS S3 file data through a Privacera DataServer proxy.
The following commands must be run in a notebook for Databricks:
Install the AWS Boto3 libraries:
pip install boto3
Import the required libraries:
import boto3
Access the AWS S3 files:
def check_s3_file_exists(bucket, key, access_key, secret_key, endpoint_url, dataserver_cert, region_name): exec_status = False access_key = access_key secret_key = secret_key endpoint_url = endpoint_url try: s3 = boto3.resource(service_name='s3', aws_access_key_id=access_key, aws_secret_access_key=secret_key, endpoint_url=endpoint_url, region_name=region_name) print(s3.Object(bucket_name=bucket, key=key).get()['Body'].read().decode('utf-8')) exec_status = True except Exception as e: print("Got error: {}".format(e)) finally: return exec_status def read_s3_file(bucket, key, access_key, secret_key, endpoint_url, dataserver_cert, region_name): exec_status = False access_key = access_key secret_key = secret_key endpoint_url = endpoint_url try: s3 = boto3.client(service_name='s3', aws_access_key_id=access_key, aws_secret_access_key=secret_key, endpoint_url=endpoint_url, region_name=region_name) obj = s3.get_object(Bucket=bucket, Key=key) print(obj['Body'].read().decode('utf-8')) exec_status = True except Exception as e: print("Got error: {}".format(e)) finally: return exec_status readFilePath = "file data/data/format=txt/sample/sample_small.txt" bucket = "infraqa-test" #saas access_key = "${privacera_access_key}" secret_key = "${privacera_secret_key}" endpoint_url = "https://ds.privaceracloud.com" dataserver_cert = "" region_name = "us-east-1" print(f"got file===== {readFilePath} ============= bucket= {bucket}") status = check_s3_file_exists(bucket, readFilePath, access_key, secret_key, endpoint_url, dataserver_cert, region_name)
Access Azure file using Azure SDK from Databricks
This section describes how to use the Azure SDK for PrivaceraCloud to access Azure DataStorage/Datalake file data through a Privacera DataServer proxy.
The following commands must be run in a notebook for Databricks:
Install the Azure SDK libraries:
pip install azure-storage-file-datalake
Import the required libraries:
import os, uuid, sys from azure.storage.filedatalake import DataLakeServiceClient from azure.core._match_conditions import MatchConditions from azure.storage.filedatalake._models import ContentSettings
Initialize the account storage through connection string method:
def initialize_storage_account_connect_str(my_connection_string): try: global service_client print(my_connection_string) service_client = DataLakeServiceClient.from_connection_string(conn_str=my_connection_string, headers={'x-ms-version': '2020-02-10'}) except Exception as e: print(e)Prepare the connection string:
def prepare_connect_str(): try: connect_str = "DefaultEndpointsProtocol=https;AccountName=${privacera_access_key}-{storage_account_name};AccountKey=${base64_encoded_value_of(privacera_access_key|privacera_secret_key)};BlobEndpoint=https://ds.privaceracloud.com;" # sample value is shown below #connect_str = "DefaultEndpointsProtocol=https;AccountName=MMTTU5Njg4Njk0MDAwA6amFpLnBhdGVsOjE6MTY1MTU5Njg4Njk0MDAw==-pqadatastorage;AccountKey=TVRVNUTU5Njg4Njk0MDAwTURBd01UQTZhbUZwTG5CaGRHVnNPakU2TVRZMU1URTJOVGcyTnpVMTU5Njg4Njk0MDAwVZwLzNFbXBCVEZOQWpkRUNxNmpYcjTU5Njg4Njk0MDAwR3Q4N29UNFFmZWpMOTlBN1M4RkIrSjdzSE5IMFZic0phUUcyVHTU5Njg4Njk0MDAwUxnPT0=;BlobEndpoint=https://ds.privaceracloud.com;" return connect_str except Exception as e: print(e)Define a sample access method to get Azure file and directories:
def list_directory_contents(connect_str): try: initialize_storage_account_connect_str(connect_str) file_system_client = service_client.get_file_system_client(file_system="{storage_container_name}") #sample values as shown below #file_system_client = service_client.get_file_system_client(file_system="infraqa-test") paths = file_system_client.get_paths(path="{directory_path}") #sample values as shown below #paths = file_system_client.get_paths(path="file data/data/format=csv/sample/") for path in paths: print(path.name + '\n') except Exception as e: print(e)To verify that the proxy is functioning, call the access methods:
connect_str = prepare_connect_str() list_directory_contents(connect_str)